
También te puede interesar:

Estas son algunas de las librerías para Python más usadas y que quizá deberías conocer si estás aprendiendo el lenguaje. Son bastante útiles, te facilitarán el desarrollo de aplicaciones avanzadas y podrás usarlas con la confianza de que funcionan y están siendo actualizadas constantemente.
- requests
- tqdm
- pillow
- scrapy
- numpy
- pandas
- scapy
- matplotlib
- kivy
- nltk
- keras
- SQLAlchemy
- Django
- Twisted
requests
Es según sus creadores Python HTTP para humanos. La librería requests te permitirá hacer peticiones por http de una manera sencilla. Cuando se hace una petición, requests automáticamente decodificará el contenido extraido de un servidor y la mayoría de caracteres unicode serán decodificados correctamente.
En este ejemplo sencillo:
import requests
r = requests.get('https://www.google.com')
print(r.text)
El resultado es el siguiente:

La página de [requests]
tqdm
Barras de progreso para Python. Las barras de progreso son bastante útiles porque ayudan a hacer que los trabajos de procesamiento de datos sean menos dolorosos entre otras cosas porque mostrarán una estimación confiable de cuánto tiempo tomará y el porque el usuario puede ver de inmediato si una tarea se ha detenido.
En el siguiente ejemplo:
from tqdm import tqdm
from time import sleep
for i in tqdm(range(1000)):
sleep(0.01)
El resultado es el siguiente:
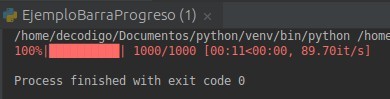
La página de [tqdm]
pillow
Una herramienta para manipular imágenes. Es un fork de PIL y es más fácil de usar, bastante útil si trabajas con imágenes frecuentemente.
A continuación un pequeño ejemplo:
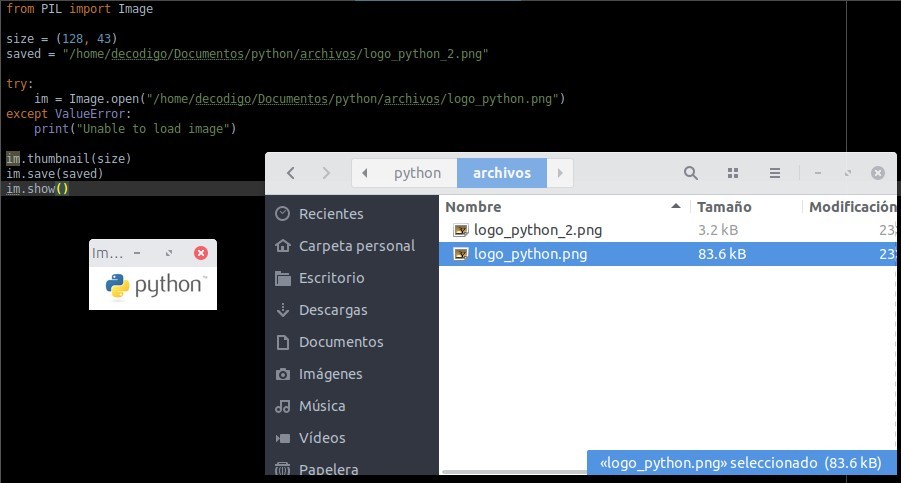
from PIL import Image
size = (128, 43)
saved = "/home/decodigo/Documentos/python/archivos/logo_python_2.png"
try:
im = Image.open("/home/decodigo/Documentos/python/archivos/logo_python.png")
except ValueError:
print("Unable to load image")
im.thumbnail(size)
im.save(saved)
im.show()
El resultado será una ventana con la imagen de tamaño diferente. Antes de mostrar la ventana se creará una nueva imagen con el tamaño asignado.
La página de [pillow]
scrapy
Scrapy es framework que te permitirá rastrear sitios web y extraer datos estructurados que pueden utilizarse para una amplia gama de aplicaciones, como la extracción de datos, el procesamiento de información o el archivo histórico.
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://blog.scrapinghub.com']
def parse(self, response):
for title in response.css('.post-header>h2'):
yield {'title': title.css('a ::text').get()}
for next_page in response.css('a.next-posts-link'):
yield response.follow(next_page, self.parse)
Aunque Scrapy fue diseñado originalmente para el rastreo web, también se puede usar para extraer datos con APIs (como los Amazon Associates Web Services) o como un rastreador web de propósito general.
Para entender más como configurar un proyecto es mejor ir a la página del proyecto.
La página de [scrapy].
NumPy
NumPy es el paquete más usado para computación científica con Python. Contiene, entre otras cosas:
- Un poderoso objeto de matriz N-dimensional
- Funciones sofisticadas (broadcasting)
- Herramientas para la integración de código C / C ++ y Fortran.
- Álgebra lineal útil, transformada de Fourier y capacidades de números aleatorios.
La página de [numpy]
pandas
Pandas es una biblioteca de código abierto con licencia BSD que proporciona estructuras de datos de alto rendimiento, fáciles de usar y herramientas de análisis de datos para el lenguaje de programación Python.
Pretende ser un bloque de construcción fundamental para realizar análisis prácticos de datos del mundo real con Python. Pandas es muy extenso y para entender mejor todo lo que puedes hacer es mejor pasar por la página del proyecto.
La página de [pandas]
scapy
Scapy permite enviar, rastrear y diseccionar y falsificar paquetes de red. Esta capacidad permite la construcción de herramientas que pueden sondear, escanear o atacar redes.
En otras palabras, Scapy es un poderoso programa interactivo de manipulación de paquetes. Es capaz de forjar o decodificar paquetes de una gran cantidad de protocolos, enviarlos por cable, capturarlos, hacer coincidir solicitudes y respuestas, y mucho más. Scapy puede manejar fácilmente la mayoría de las tareas clásicas como escaneo, rastreo de rutas, sondeo, pruebas unitarias, ataques o descubrimiento de redes. Puede reemplazar hping, arpspoof, arp-sk, arping, p0f e incluso algunas partes de Nmap, tcpdump y tshark)
La página de [scapy]
Matplotlib
Matplotlib es una biblioteca de trazado 2D que produce gráficas de buena calidad en una variedad de formatos y entornos interactivos. Podrás generar gráficas, histogramas, espectros de potencia, gráficas de barras, gráficas de errores, diagramas de dispersión, etc., con unas pocas líneas de código.
La página de [Matplotlib]
Kivy
Kivy es una biblioteca de software de código abierto para el rápido desarrollo de aplicaciones equipadas con interfaces de usuario novedosas, como las aplicaciones multitáctiles. Es proyecto multiplataforma con un módulo para Python 2 y Python 3.
La página de [kivi]
NLTK
NLTK es una plataforma líder para la creación de programas en Python para trabajar con datos en lenguaje humano. Proporciona interfaces fáciles de usar para más de 50 recursos corporales y léxicos, como WordNet, junto con un conjunto de bibliotecas de procesamiento de texto para clasificación, tokenización, derivación, etiquetado, análisis y razonamiento semántico, wrappers para bibliotecas NLP muy solidas.
La página de [NLTK]
Keras
Keras es una API de redes neuronales de alto nivel, escrita en Python y capaz de ejecutarse sobre TensorFlow, CNTK o Theano. Fue desarrollada para permitir a los desarrolladores experimentación rápida. Con al filosofía de «Poder pasar de la idea al resultado con el menor retraso posible es clave para hacer una buena investigación».
La página de [Keras]
SQLAlchemy
SQLAlchemy es el kit de herramientas SQL para Python y un mapeador relacional de objetos que ofrece a los desarrolladores de aplicaciones el máximo poder y flexibilidad de SQL.
Proporciona un conjunto completo de patrones de persistencia conocidos a nivel empresarial, diseñados para el acceso a bases de datos eficientes y de alto rendimiento.
La página de [SQLAlchemy]
Django
Django es un framwork web para Python de alto nivel que fomenta el desarrollo rápido y el diseño limpio y pragmático. Creado por desarrolladores experimentados, se encarga de gran parte de las complicaciones del desarrollo web, por lo que podrás concentrarte en escribir aplicaciones sin necesidad de reinventar la rueda. Es gratis y de código abierto.
La página de [django]
Twisted
Twisted es un framework de red que se basa en el paradigma de la programación dirigida por eventos, quiere decir que los usuarios de Twisted pueden escribir pequeños callbacks (retrollamadas) predefinidos en el framework para realizar tareas complejas. Está bajo la licencia MIT.
La página de [Twister]